Open-sourcing JustJoinIT job board dataset (2021-2023)
/ 5 min read
Introduction
In 2021, I wanted to work on some side project that would include processing real dataset collected from the internet. After doing some research, I chose JustJoinIT (one of the biggest IT job boards in Poland) because:
- they had a lot of IT job offers listed on their website (with proper categorization)
- a lot of their listings had a salary range included (which is not that popular among other competitors from Poland - although it’s getting better)
- job offers data could be easily accessed via HTTP API
I’ve never finished the project due to lack of time and willingness, but I kept the data collection process working for almost 2 years (October 2021 through September 2023) and, after all, I ended up creating an interesting dataset and decided to share it with other people.
If you’d like to jump straight into the data, then you can find it on Kaggle.
In the rest of the article I go through:
- data collection architecture (on AWS)
- mistakes I made during the process
- how much I paid for cloud resources
Data collection setup
When browsing JustJoinIT website and inspecting network traffic through Developer Tools tab, I saw that frontend makes a request to a publicly available HTTP endpoint to fetch a JSON containing all job offers.
I decided to go with following architecture to enable data collection process:
- S3 for storing JSON files extracted from API
- Small Python script wrapped into AWS Lambda function for compute (calling HTTP API and saving data to S3)
- EventBridge Rule for scheduling AWS Lambda function (once a day)
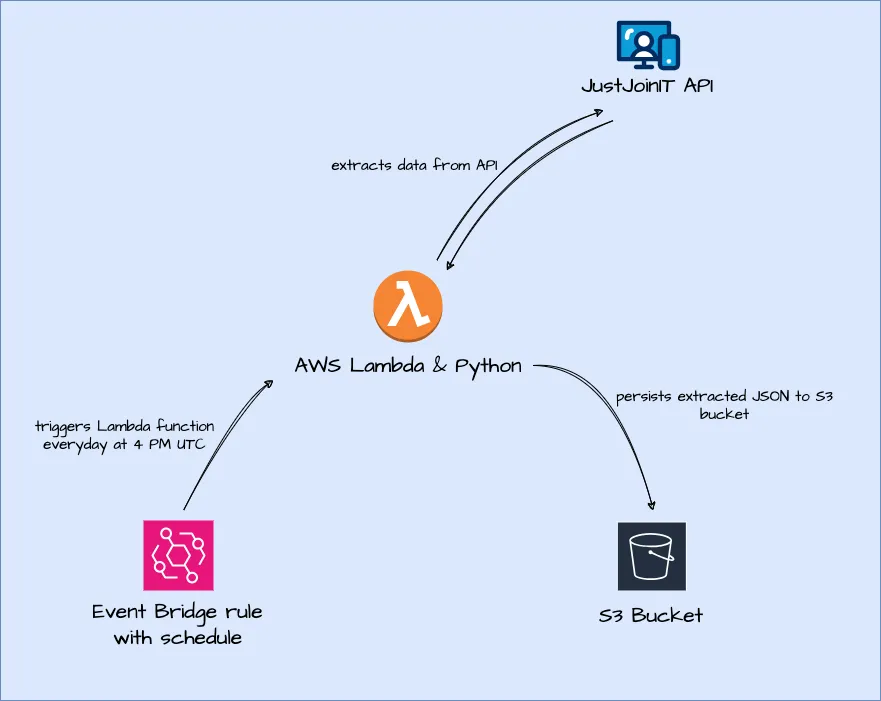
Above architecture is serverless - compute resources are utilised only when they’re needed (thanks to AWS Lambda and EventBridge).
JSON payload extracted from JJIT API was not transformed in any way - any data cleansing, quality checks and similar steps were supposed to be executed in later stage of the pipeline.
What mistakes have I made?
There are over 30 days missing in the dataset because of mistakes I made during coding the data collection process.
Initial version looked something like this:
1. Calculate today's date
2. Call JustJoinIT HTTP endpoint
3. Save extracted JSON response under s3://<bucket name>/jjit-data/<year>/<month>/<day>.jsonWhat went wrong?
No retry for HTTP call
There was no retry mechanism implemented. Lots of things might happen when data travels over the wire. Without checking for failures and attempting retries, data for particular day would get lost.
The part of code that persisted data to S3 was more reliable as boto3 implements retry strategy by default (see docs for more info).
No notification mechanism about failures
I haven’t implemented any mechanism that would let me know that something went wrong. I actually spotted a missing day by accident when browsing S3 bucket.
To fix that, I added SNS topic and created an email subscription to it. Upon failure, a message with details would be published to this topic and I’d receive an email notification.
Leaving default Lambda timeout
By default, Lambda function defaults to 3 seconds timeout. It turned out to be a little low (payloads received from JJIT API were sometimes ~15MB of size). Increasing this timeout to 15 seconds solved the issue.
Storing uncompressed JSONs in S3
This one didn’t cause any gaps in the data but it had an impact on overall cost ;-).
I haven’t used any compression and stored JSON data as plain text in S3 bucket. At the end, the dataset grew up to 8.5GB of data.
When I decided to open source this dataset on Kaggle, I created a small Python script to zip days of specific month into a single ZIP archive. It turned out that whole data weighed ~1GB when compression was applied. Since S3 storage was the only component that generated any costs, I could potentially reduce it 8 times (but it was not that much of a problem when considering overall costs).
How much have I paid for collecting data over 2 years?
As mentioned earlier, S3 was the only service that appeared in my monthly bill. AWS Lambda & EventBridge usage were within their free tiers and I didn’t have to pay anything for compute.
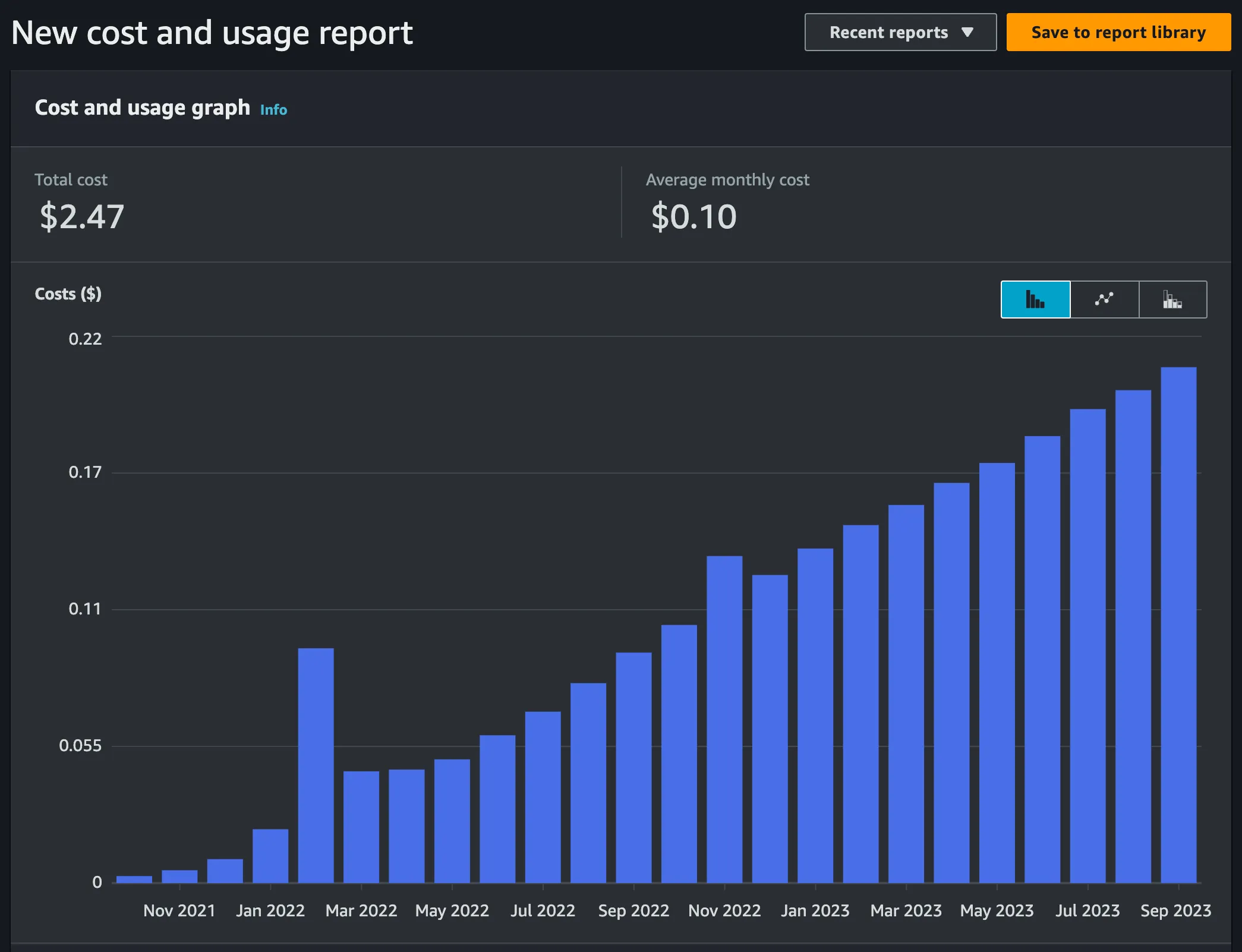
S3 storage bill was slowly increasing and, at the end of data collection stage, it cost 0.26$ (0.21$ of service usage and 0.05$ being VAT tax).
Total cost of S3 service between October 2021 and September 2023 was 2.47$:
Will I extend published dataset with new data?
No. JustJoinIT change the way they serve data to their frontend application and I’d have to write some kind of web scraper from scratch. September 25th was the last captured day before this change.
How is this dataset useful for you?
Majority of job offers come from Poland and insights extracted from this data would be of highest interest to people living there. However, if you’re looking for a dataset to practice things like data analytics / visualization / data cleaning, give it a shot :-)!
The end
Thanks for reading this post. Again, here’s the link to dataset on Kaggle.
Best Regards,
Kuba
(1/52) This is a first post for my blogging challenge (publishing 52 posts in 2024).