
I’ve recently came across the One Billion Row Challenge by Gunnar Morling. In this article I am comparing of a simple naive solution written in Python and executed on 2 different Python’s implementation: CPython and PyPy.
One billion rows challenge
One billion rows challenge (often shortened to just 1br challenge) is about reading a text file containing 1 billion rows containing temperature measurements and aggregating min, mean, max per weather station and displaying the output in an alphabetical order like this:
{Abha=5.0/18.0/27.4, Abidjan=15.7/26.0/34.1, Abéché=12.1/29.4/35.6, Accra=14.7/26.4/33.1, Addis Ababa=2.1/16.0/24.3, Adelaide=4.1/17.3/29.7, ...}Original challenge’s goal was to compute these stats as quickly as possible while using Java, however internet was quickly flooded with numerous implementations in other languages.
When I’m writing this article, the best Java solution performed these calculates just under 8 seconds (00:07.999 to be exact).
Note that execution time is dependant on the underlying hardware and, to be able to compare the submissions, Gunnar benchmarks them on the same type of machine - Hetzner Cloud CCX33 instance (8 dedicated vCPU, 32 GB RAM)
Pythons duel
Since I’m using Python for day to day job, I was curious about its performance in this challenge.
Obviously, it has to be slower (probably much slower) than statically typed languages - especially if you stick with the standard library and don’t use libraries such as Polars or Pandas which leverage Rust or C speed).
It was also a good opportunity to do a little comparison between regular Python (CPython implementation) with its alternative called PyPy (which claims to be on average 4.8 times faster than CPython 3.7).
Reference code
Here’s the code I used for comparing the timings:
import time
from datetime import timedelta
def print_stats(stats):
formatted = ", ".join(
[
f"{k}={v['min']}/{v['sum']/v['count']:.1f}/{v['max']}"
for k, v in sorted(stats.items(), key=lambda x: x[0])
]
)
print("{" + formatted + "}")
def calculate_stats(filepath: str):
stats = {}
with open(filepath, "rt") as f:
for row in f:
city, temp_str = row.strip().split(";")
temp = float(temp_str)
if city in stats:
city_stats = stats[city]
city_stats["min"] = min(city_stats["min"], temp)
city_stats["max"] = max(city_stats["max"], temp)
city_stats["sum"] += temp
city_stats["count"] += 1
else:
stats[city] = {
"min": temp,
"max": temp,
"sum": temp,
"count": 1,
}
return stats
if __name__ == "__main__":
start_time = time.monotonic()
measurements_path = "/path/to/1br/file.txt"
print_stats(calculate_stats(measurements_path))
time_elapsed = round(time.monotonic() - start_time, 2)
print(f"Total application time: {timedelta(seconds=time_elapsed)}")Function calculate_stats goes through provided file line by line (we use iterate to avoid loading whole file into memory as it weights over 12GB) and parses it into weather station string and a temperature measurement float.
Parsed data is aggregated in a stats dictionary which maps weather stations to dictionary with its statistics (min, max, sum and count). Sum and count will be later used for calculating average (so that we don’t have to store a list with all measurements for calculating mean value).
If weather station already exists, we use built-in min and max functions to determine if parsed temperature is smaller/greater than the values we already have and we increment the sum and count values. Otherwise, we instantiate a dictionary filled with parsed temperature value and count = 1.
print_stats function prints the aggregated results in the format that is expected by 1BR challenge.
Installing PyPy
I use pyenv for managing multiple Python versions on my local machine.
To see available pypy versions, type:
pyenv install -l | grep pypyI’ll use pypy3.9-7.3.11 for this experiment:
pyenv install pypy3.9-7.3.11Let’s make it our local version:
pyenv local pypy3.9-7.3.11And it’s ready:
$ pypy
Python 3.9.16 (feeb267ead3e6771d3f2f49b83e1894839f64fb7, Dec 29 2022, 15:36:58)
[PyPy 7.3.11 with GCC Apple LLVM 13.1.6 (clang-1316.0.21.2.5)] on darwin
Type "help", "copyright", "credits" or "license" for more information.Results
I am using a Mac Book Pro 2019 with 2,6 GHz 6-Core Intel Core i7 processor (12 cores) and 16GB of RAM.
For comparing CPython and PyPy, I used 3.9 versions for both implementations. On top of that, I executed the same code using Python 3.120a4 (just to check how noticeable are the performance improvements added in 3.11)
Besides Python executions, I also tested the baseline Java application available in 1BR repo (there’s no point to compare it against Python runs as the code is different - it’s here just out of my curiosity).
Results look as following:
| interpreter/language | total time (seconds) |
|---|---|
| CPython (3.9) | 1216 |
| CPython (3.12) | 1032 |
| PyPy (3.9) | 585 |
| Java | 216 |
And if put into a simple chart:
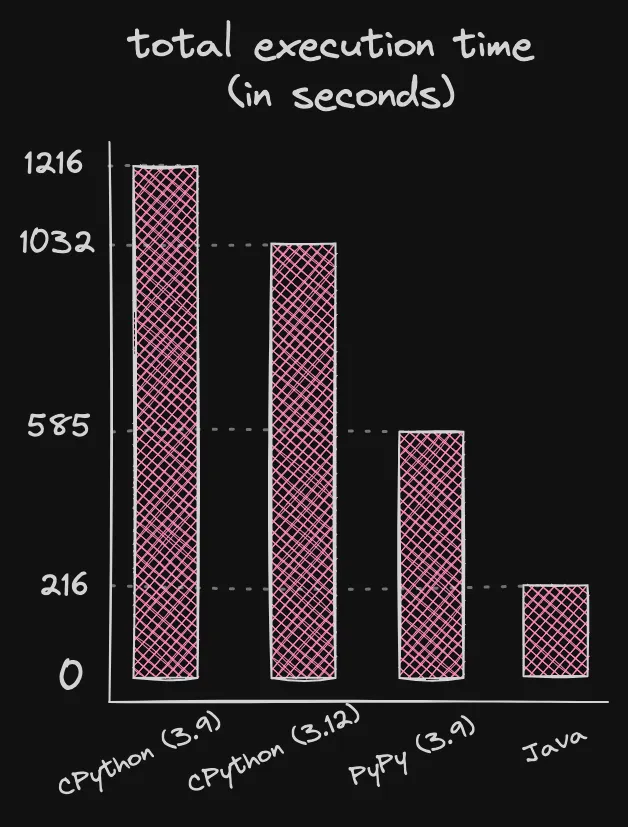
As you can see, PyPy’s execution time is 2 times faster when compared CPython 3.9 and 1.76 faster compared to CPython 3.12. Nice!
Can Python do better?
Definitely - see this solution. Reading file in chunks and processing chunks in separate process allowed author to go below 1 minute. Remember that execution time is dependent on the underlying hardware (processor speed, available cores) as my machine needed ~2.5 minutes to process 1 billion rows with this code.
(5/52) This is a 5th post for my blogging challenge (publishing 52 posts in 2024).